





You are crafting your beautiful application, paying extra attention to detail, but your boss is breathing down your neck saying: "Ship! Ship! Ship! 🚢 ".
Shortcuts are taken. Mistakes are made. Your bug goes into Prod, and now you have an outage.
Maybe you've failed to try out your new feature on real-world data, and a bad query is now hammering your database, which does not scale.
You didn't have time to cover all scenarios on realistic datasets.
You didn't have time to write the extra tests.
You didn't think of all the possible scenarios.
This is where you, as a developer, throw your arms up in despair and say: "time pressure!"
I admit it, I absolutely love a good "I told you so!". We warned you, Evilboss, and now look what happened!

While time pressure may be a significant contributing factor, I also firmly believe developers can do much better, even under the constraint of time. Focusing on this one issue is a distraction.
The Root Cause
"Find the Root Cause" is a common phrase. What happened? They ask. The answer is usually – a bug.
However, we must think beyond that to improve our software craft.
Typical flow
If your dev outfit is more than one or two developers, you likely have a release process of some sort. Typically it would be a variant of something like the diagram below.
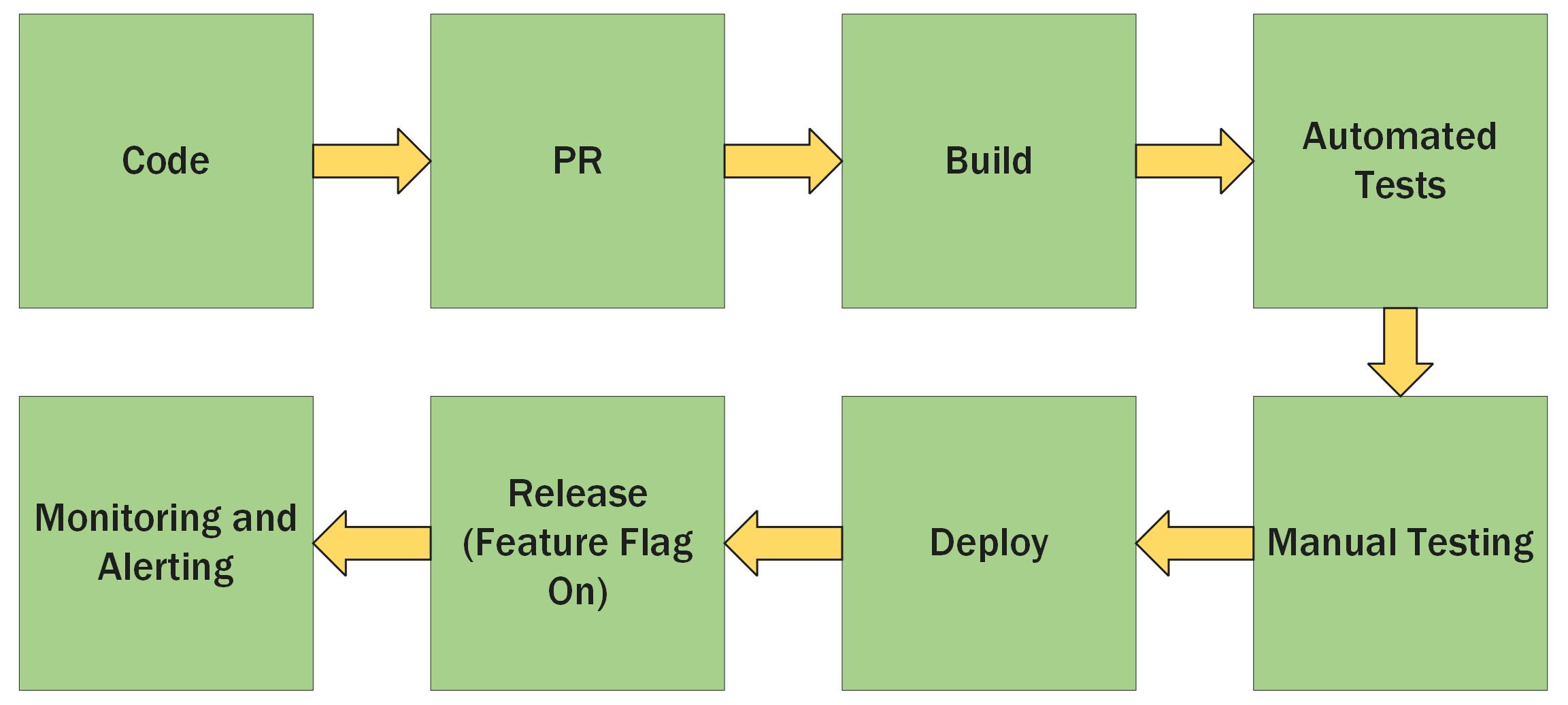
You may have more or fewer steps, but if you're entirely missing something like testing, that is a red flag that something is already not quite right.
You typically go through all these layers for something to be released, even in a rush. You can move through this flow quickly while minimising problems if this flow is set up well.
Failures in the flow
When something has failed, look at your version of your development flow above.
Assume that humans are fallible and will write bugs. You cannot prevent that.
Where could your issue have been caught, after the code has been typed but before it hits prod? It may be one or two steps or all the steps, or maybe you need an extra step.
Returning to our example, a bad API is written that is not tested with production data, causing chaos on the database in prod. These are questions you could ask:
Code – a bug is written
Did the developer call a dependency that was not well documented?
Was it a junior working without enough support?
Was there a lack of sound patterns to follow?
Was there an unintended side effect from a complicated legacy method?
Is there fragile legacy code that needs a clean-up?
Peer Review (PR) – bug is approved
Are your PRs just rubber stamps?
Was the peer reviewer not qualified?
Was there too much code in one PR?
Build – build is kicked off and passes
Do you have unit tests as part of the build?
Do you have good patterns for unit tests to cover similar scenarios?
Do you have linting or other static code checking?
Automated Tests – integration tests or end-to-end tests
Is your test dataset realistic?
Do you cover performance?
Are your tests flaky and are now just being ignored?
Deployment and Release – code is deployed, then a feature flag is turned on
Do you have a rollback plan? Feature flag off?
Can you release a feature to 10% of users for the first few hours to test for errors and performance issues?
Monitoring and Alerting – this can be an ambulance at the bottom of the cliff, but an important one.
Did your alerts tell you about the problem, or did your users?
How soon did your alerts go off after the problem was shipped? Can you narrow this time?
Critically look through all this, and then identify the most impactful improvements that can be made.
Idealism vs Reality
Not every company can have all the steps above; not everyone is open to change. We don't all live in idealistic blog posts or ride unicorns.

This is where you use the failure to your advantage, show your bosses and coworkers that things need to improve, and then start working towards it bit by bit. You do not need permission to do this!
One test here. One good pattern to follow in the future. A couple of PR comments to your workmates to nudge them towards doing things a little better each time too.
I have seen dreadful codebases at companies with dreadful cultures improve through small iterations made by people who care to improve.
And your results at the end of it will most likely be appreciated. If not, take the experience from doing this to somewhere else where it will be recognised.
Back to Time Pressure
Yes, time pressure sucks and makes things worse. You should absolutely raise it as an issue, propose more reasonable alternatives and the like. But you will still have to deal with too much work to squeeze into too little time as part of life.
When time pressure is there, and it is not budging, embrace it as being another constraint, part of an elegant puzzle that needs solving.
What do you think? Leave a comment down below.